 Fm Golfo Azul Villa Pehuenia
Fm Golfo Azul Villa Pehuenia

Puede que no te hayas parado a pensarlo, pero hay una realidad llamativa en el mundo de los chatbots: es más caro hablar en español con la IA que hacerlo en inglés.
La razón es sencilla: la IA no entiende de palabra, entiende de tokens. Y cuando hablas con GPT, Gemini, Claude o cualquier otro LLM, tú le hablas en un idioma, pero para entenderte él primero «traduce» lo que le estás diciendo y lo convierte en tokens. Y el problema es precisamente ese: que no todos los idiomas «cuestan» lo mismo en términos de tokens.
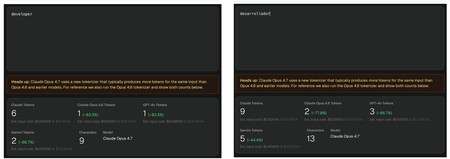
Hay un ejemplo muy sencillo que podemos analizar gracias a herramientas como ClaudeTokenizer: la palabra «desarrollador», que en inglés es «developer» cuesta pocos o muchos tokens según el idioma en que la escribamos y también (importante) la versión del modelo de IA utilizada. En la imagen se ve claramente, pero por si acaso, resumimos:
- Para ChatGPT (GPT-4o y GPT-5) la palabra «desarrollador» tiene tres tokens (des-arroll-ador), pero la palabra «developer» solo cuesta uno.
- Para Claude (Opus 4.7) la palabra «desarrollador» cuesta nada menos que 9 tokens (2 en Opus 4.6), pero «developer» cuesta «solo» 6 (1 en Opus 4.6).
¿Qué está pasando aquí?
Pues que cada modelo de lenguaje utiliza su propio «tokenizador», su «traductor» de un idioma convencional al idioma de tokens que entiende el modelo de lenguaje. Y esos tokenizadores favorecen precisamente los idiomas en los que estos modelos están creados.

Así entiende la IA cómo hablamos. Cada palabra se divide en tokens, y el inglés se entiende mucho mejor. «developer» solo cuesta un token en GPT-5, pero «desarrollador» se descompone en tres. Malas noticias para los hispanoparlantes.
De hecho, el inglés se ha convertido en el idioma oficial de la inteligencia artificial, lo queramos o no. La razón no es cultural, sino arquitectónica: el 95% de los datos de entrenamiento de los modelos frontera (GPT-5, Gemini 3.1, Claude Opus/Sonnet 4.7…) están en ese idioma.
Eso hace que el resto de idiomas sean «idiomas extranjeros», y eso hace necesario que al usarlos uno pague un extra, un peaje casi invisible en cada interacción. En términos prácticos, lo que pasa cuando usamos el español para hablar con un modelo de IA es sencillo: usamos más tokens, y por tanto usar español es sencillamente más caro que usar el inglés al trabajar con un gran modelo de lenguaje.
Si quieres ahorrar tokens, mejor usa el inglés
La pregunta, claro, es ¿Cuánto más nos cuesta hablar en español que en inglés con ChatGPT (GPT 5.x) o con Claude Opus 4.7?
Es difícil decirlo porque cada palabra y cada frase es un mundo, pero lo cierto es que el inglés suele ser casi siempre el más «económico». Hemos utilizado una de las primeras frases de este artículo para comparar ese consumo de tokens, y al traducir la frase a distintos idiomas y consultar ese consumo en tokens para distintos modelos, los datos son claros.

Es importante destacar que estos resultados no son concluyentes, pero sí dejan clara la tendencia: el inglés es el idioma más eficiente en cuanto a consumo de tokens, pero cuidado, porque el español no está tan mal, y suele ser el segundo más eficiente. Incluso es más eficiente que el inglés en Gemini, al menos según la herramienta consultada.
Pero de media lo normal es que haya un sobrecoste llamativo al usar distintos modelos. Una conversación con Claude Opus 4.7 ya es «cara» porque es uno de los modelos más caros actualmente, pero en español es casi un 30% más cara, y no digamos en árabe, un 76,3% más cara.
De hecho según este ejemplo la diferencia entre Claude o GPT-4o en cuanto a eficiencia es clara: el tokenizador de OpenAI es «más económico», y aunque puede haber diferencias con GPT-5.x, lo que parece claro es que en Anthropic han preferido «gastar más» para obtener mejores resultados (o ese es el objetivo). Gemini es aún más ahorrador según estas pruebas, y puede que eso también tenga mucho que ver con la calidad de las respuestas, aunque esa cuestión da para otro tema.
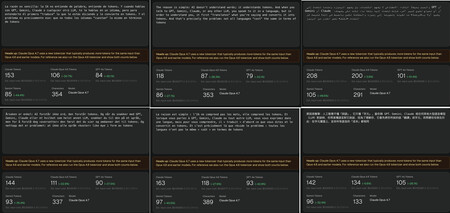
Hemos usado uno de los párrafos de este artículo en español y lo hemos tradudcido con Deepl al inglés, árabe, noruego, francés y chino para saber cuántos tokens «costaba» la frase en cada idioma. El inglés es sin duda el más eficiente
Los tokenizadores avanzan y evolucionan. Algunas veces lo hacen para ahorrarnos tokens, como pasó con el tokenizador de GPT-4o: en aquel momento OpenAI explicaba cómo esa herramienta usaba 1,1 veces menos tokens al hablar con ella en español pero hasta 2,9 veces menos en hindi o 3,5 veces menos en telugu. Con Claude Opus 4.7 ha pasado justo lo contrario: el tokenizador se ha rediseñado y consume más tokens (hasta 1,35 veces más, admitían) con el objetivo de procesar y entender mejor el texto.
Tu chatbot piensa (y programa) en inglés
Aquí hay que destacar también algo importante: aunque podemos hablar con nuestro chatbot preferido en cualquier idioma y él nos contestará en ese idioma (salvo que le pidamos otra cosa), los modelos de IA «piensan en inglés».
Es decir: cuando tú conversas con ellos lo que hacen es traducir lo que les dices para luego razonar en inglés y finalmente traducen su respuesta al idioma en el que les estabas hablando. Eso consume tokens de razonamiento adicionales, pero además también tiene cierto impacto en la latencia (lo que tarda en empezar a pensar o en contestar el modelo). En tareas complejas eso puede influir claramente en los tiempos de respuesta por la sencilla razón de que el modelo de IA no para de traducir de «su idioma oficial» (el inglés) a nuestro idioma.
Esa preferencia por el inglés se nota también en los benchmarks: en el Humanity’s Last Exam, en el que se realizan a los modelos todo tipo de preguntas de conocimientos generales con varias opciones para contestar, es razonable pensar que los modelos contestan mejor en inglés porque ese examen está diseñado en ese idioma.

No sabemos qué miden los benchmarks de IA. Así que hemos hablado con el español que ha creado uno de los más difíciles
En tareas de programación ese uso del inglés también favorece los resultados. Hay estudios específicos que tratan el tema y dejan claro que si estás usando IA para programar, no es mala idea que «le hables» en inglés directamente. La razón sigue siendo la misma que habíamos mencionado: la inmensa mayoría de los datos de entrenamiento de programación precisamente están en inglés porque este ya era de facto el «idioma oficial» de los programadores antes de que apareciese la IA.
También hay diversos estudios que confirman desde hace años que el inglés es el idioma más eficiente a la hora de conversar con modelos de IA, pero también apuntaban a cómo soportar mejor varios idiomas puede contribuir a que el uso multiidioma sea no solo factible, sino eficiente.

Google ya sabe cómo hacer que sus AI Overviews sean más humanas: usar el contenido de Reddit sin piedad
En este estudio del junio de 2025 de investigadores de Microsoft, los autores indicaban precisamente eso: «el prompting multiidioma puede reducir el uso de tokens entre un 20 y un 40% sin que la precisión se vea comprometida, lo que plantea una estrategia simple y efectiva para mejorar la eficiencia de la inferencia sin necesidad de un reentrenamiento».
En ese estudio se usaban modelos como Qwen o DeepSeek para indicar que razonar en español o en chino podía ser más eficiente, pero cuidado, porque insistimos: cada modelo es un mundo y lógicamente los modelos desarrollados en EEUU tienen una preferencia absoluta por el inglés en cuanto a datos de entrenamiento.
Pero entonces, ¿uso el inglés o puedo seguir en español?
Si uno se fija en esos datos, la conclusión parece clara: si podemos, deberíamos hablar con la IA en inglés directamente. La realidad es algo distinta.
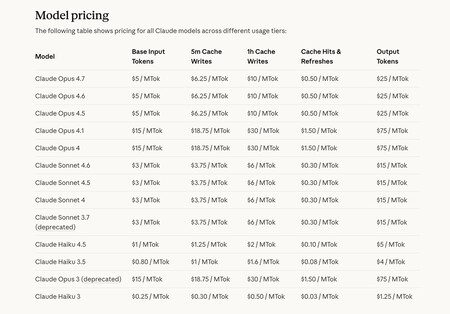
Cuando uno usa modelos de IA mediante las APIs (pagas lo que usas), quizás no es mala idea intentar usar el inglés para hablar con estos modelos. En la imagen, los precios para distintos modelos de Anthropic.
Sobre todo, porque los precios de uso de la IA no paran de caer y eso hace que el sobrecoste del uso de tokens que se usan al hablar en español sea probablemente irrelevante para el uso doméstico. No solo eso: la mayoría de usuarios aprovechan planes mensuales como ChatGPT Plus o Claude Pro (por ejemplo), y en esos planes tenemos una especie de «pseudotarifa plana».
Estos planes no son ilimitados, desde luego, y si los usamos de forma intensiva nos encontraremos con el temido «lo siento, tendrás que esperar hasta dentro de cinco horas para poder volver a seguir usando este modelo». Sin embargo llegar a esos límites es complicado para un uso moderado, y aquí usar los modelos en inglés o en español no es demasiado importante.
Es cierto que en algunos ámbitos usar el inglés tiene ventajas, no solo a nivel de eficiencia (los tokens «nos duran» más), sino también de precisión. Eso puede ocurrir en tareas más complejas como la programación, y ahí usar prompts en inglés puede ayudar a obtener resultados que quizás en español u otros idiomas no acabamos de obtener.

Anthropic se ha convertido en la Apple de nuestra era y OpenAI en nuestra Microsoft: una historia de amor y odio
Las cosas cambian un poco si usamos modelos de IA mediante las APIs de estas plataformas. Aquí no hay pseudotarifas planas, y uno paga por lo que usa, así que ahorrar en tokens puede llegar a ser importante sobre todo si somos usuarios intensivos (y si usamos APIs suele ser porque los modelos se usan de forma especialmente intensiva). Ahí sí puede ser interesante utilizar los modelos directamente en inglés, porque eso lo notaremos claramente en el bolsillo.
En Xataka | La “economía de los tokens” se ha roto: las tarifas planas de IA para programar son matemáticamente insostenibles
–
La noticia
Si la pregunta es si usar ChatGPT o Claude en inglés es más eficiente y ahorra tokens, la respuesta es: yes
fue publicada originalmente en
Xataka
por
Javier Pastor
.

